
NeurIPS 2025🔬Why 1+1<1 in Visual Token Pruning: Beyond Naïve Integration via Multi-Objective Balanced Covering
Published:
Congratulations! Professor Xiong’s paper has been accepted to NeurIPS 2025! We are thrilled to announce that the research work by Professors Zhan and Xiong, titled **“Why 1+1<1 in Visual Token Pruning: Beyond Naïve Integration via Multi-Objective Balanced Covering,”** has been officially accepted to **NeurIPS 2025**, a premier conference in artificial intelligence! Addressing the critical challenge of inefficient inference in large vision-language models, this paper provides a deep analysis of the inherent trade-off between two key objectives in visual token pruning: **visual fidelity** and **prompt alignment**. For the first time, the authors leverage geometric covering theory to derive a closed-form upper bound on pruning error and quantify the optimal achievable performance for both objectives under a fixed token budget. Building upon this theoretical insight, the team proposes a novel **Multi-objective Balanced Covering (MoB)** algorithm. MoB reformulates token pruning as a bi-objective covering problem and introduces a greedy radius-trading strategy that transforms the complex multi-objective trade-off into a simple budget allocation problem—enabling significant acceleration while preserving high performance. 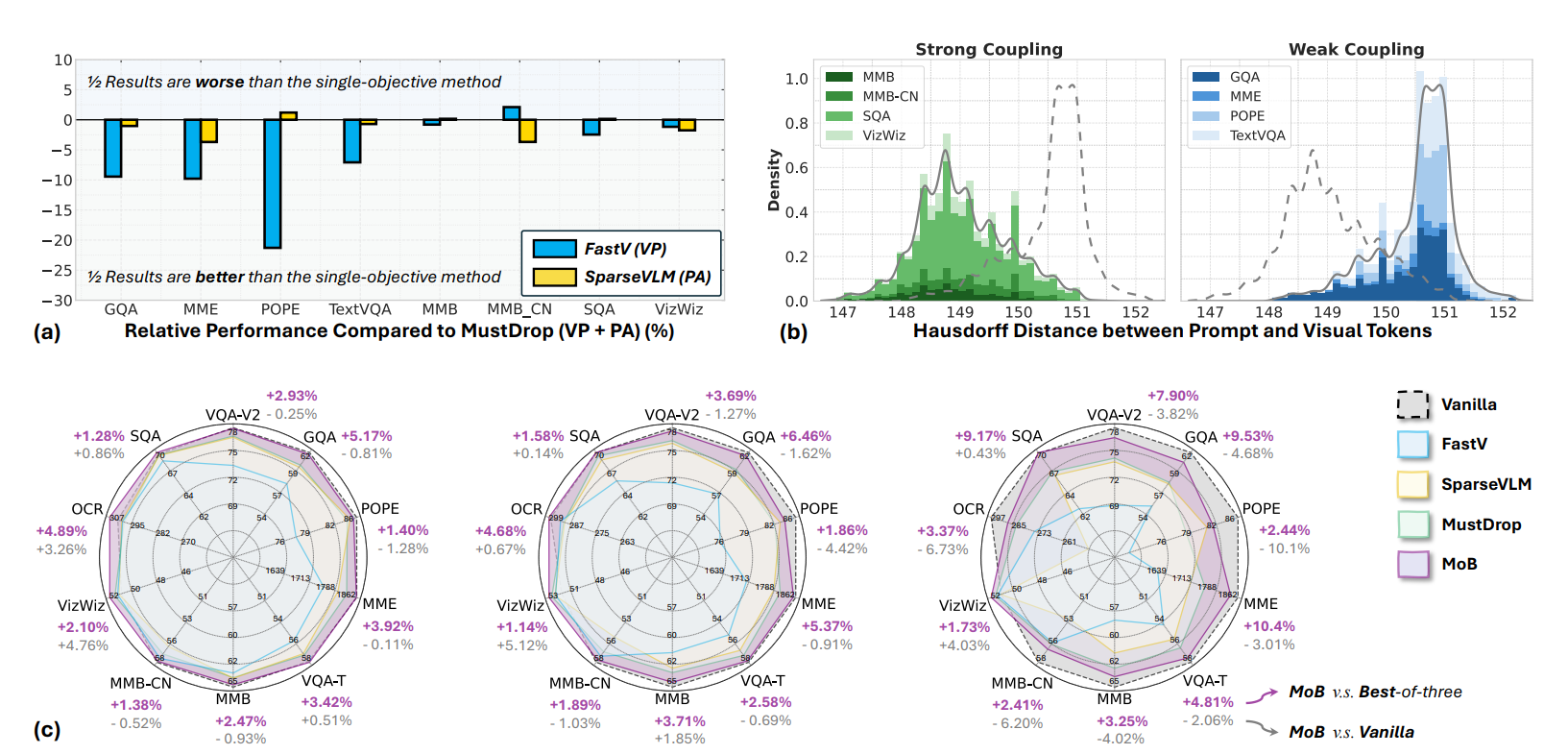 Extensive experiments demonstrate MoB’s exceptional effectiveness across multiple state-of-the-art multimodal large models, including LLaVA, Qwen2-VL, and Video-LLaVA: - On **LLaVA-1.5-7B**, MoB retains **96.4%** of the original performance while keeping only **11.1%** of the visual tokens. - On **LLaVA-Next-7B**, it achieves **1.3–1.5× speedup** with negligible performance degradation. Moreover, MoB integrates seamlessly into advanced models, showcasing remarkable **generality and practicality**.